108. 二分探索
放送大学で取り上げられた二つ目の探索の方法がここで紹介する二分探索である。
数多くある配列の中から探す、とか近似値を算出する方法として
全体を二つに分割して小さいほうにあるのか、大きいほうにあるのか判断を
繰り返す手法である。
この理論は理解している人は多いはずであるが実際のソースとなると
具体的な記述が難しいというか、なかなか想像できない。
そこでここでは放送大学で放送されたソースを IBM System i でも
実行可能なソースに書き換えたものを紹介する。
【 サンプル・ソース:TESTBINS 】
0001.00 #include <stdio.h>
0002.00 #include <stdlib.h>
0003.00 #include <string.h>
0004.00
0005.00 #define TRUE 0
0006.00 #define FALSE -1
0007.00
0008.00 int binary_search(int a[], int key, int num);
0009.00 void main(void){
0010.00 int a[10], key = 25, num;
0011.00
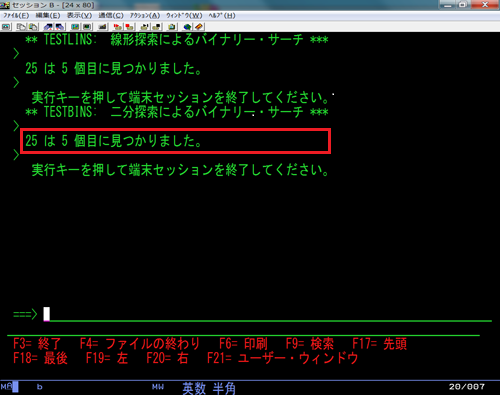
0012.00 printf("** TESTBINS: 二分探索によるバイナリー・サーチ ***\n");
0013.00 getchar();
0014.00
0015.00 a[0] = 0; a[1] = 5; a[2] = 10; a[3] = 15; a[4] = 20;
0016.00 a[5] = 25; a[6] = 30; a[7] = 35; a[8] = 40; a[9] = 45;
0017.00 if((num = binary_search(a, key, 10)) == FALSE){/* 失敗 */
0018.00 printf(" 配列には見つかりませんでした。 \n");
0019.00 getchar();
0020.00 }/* 失敗 */
0021.00 else{/* 成功 */
0022.00 printf("%d は %d 個目に見つかりました。 \n", key, num);
0023.00 getchar();
0024.00 }/* 成功 */
0025.00 return;
0026.00
0027.00 }
0028.00 /*******************************************/
0029.00 int binary_search(int a[], int key, int num)
0030.00 /*******************************************/
0031.00 {
0032.00 int middle, low, high;
0033.00
0034.00 low = 0;
0035.00 high = num + 1;
0036.00
0037.00 while(low <= high){/*while*/
0038.00 middle = (low + high)/2;
0039.00 if(key == a[middle]){/*FOUND*/
0040.00 return middle;
0041.00 }/*FOUND*/
0042.00 else if(key < a[middle]){/* 小 */
0043.00 high = middle - 1;
0044.00 }/* 小 */
0045.00 else{/* 大 */
0046.00 low = middle + 1;
0047.00 }/* 大 */
0048.00 }/*while*/
0049.00 return FALSE;
0050.00 }
【解説】
探索する配列の対象の範囲の最小の指標を low, 最大の指標を high と定義している。
そこで low と high のあいだの middle = (low + high)/2 中間の指標の値 a[middle] が
探索キー key と比較して 同じであれば、求める探索は見つかったであるから return middle として終了する。
key のほうが小さいのであれば high を high = middle - 1 として high の値を置き換えることによって
探索の範囲を半分にする。
逆に key のほうが大きいのであれば low を low = middle + 1 として low の値を置き換えることによって
探索の範囲を繰り返す。
このようにして low と high の範囲を徐々に狭くしていって最後に middle を見つけるものである。
while 文をすべて繰り返しても見つからなかったのであれば、return FALSE で戻す。
二分探索は線形探索に比べて無駄なくかなり速い処理となる。
例えば、100万個の配列を線形探索で探索してみると、見つかるまでの平均比較回数は 50万回であるのに
対して二分探索であれば約 20 回で見つけることができる。
(二分探索の比較回数は log2N として算出される。2 を底とする LOG (対数)は高校1年の教科書を
思い出して ! )
ただし、この二分法が使えるための前提となる条件は探索の対象となる配列が事前に昇順に分類( SORT )
されている必要がある。
とはいうものの二分探索の方法は単純に比較を繰り返す線形探索に比べて圧倒的に効率よいことが
これでわかる。
実は IBM System i の DB2/400 のキーによる検索も原則はこの方法によって検索されている。
読者が自分が開発する適用業務の中でも配列を用意して探索を行う場合にも応用できる。
RPG であれば LOOKUP によって配列内を検索することができるが LOOKUP も中では線形探索が
行われているのである。
二分探索のこの手法は覚えておいて損はないだろう。
何かのときにはこの記事があったことを思い出して欲しい。
【実行結果】