漢字を始めとする全角文字は同じであるが半角に関しては UTF-8 は
ASCII と同じ半角英数字であると理解していれば、ほぼ間違いない。
また CCSID に関しては
| UNIコード | CCSID |
|---|---|
| UTF-16 UTF-8 |
1200 1208 |
参考までに CCSID 1399 は UNIコードではない。
CCSID 1399 は UNIコードとは何の関係もない。
UNIコードの漢字は 3バイト、でも CCSID 1399 の漢字は EBCDIC の2バイトである。
CCSID 1399 が UNIコードであるはずがない。
これは IBM が CCSID 1399 を追加した旨の発表レターを日本IBM が誤訳して発表したからに過ぎない。
さて、UNIコード、特に UTF-16 への変換はどのように記述すればよいだろうか ?
UTF-8 への変換は iconv 関数を使って簡単にできるのでUTF-16 への変換も iconv への
パラメータをセットするだけで変換できるかというと実際、やってみるとそう簡単ではない。
さらに UTF-16 に変換する必要があるのは弊社では PDF変換のためのツール(Spoolライター)を
開発して販売しているが国際言語対応で EBCDICコードを UTF-16の UNIコードに変換する必要が
あるからである。
中国語のPDF では Shift_JIS のような言語独自のコードはないのでPC側では中国語の場合は
UNIコードを使用する必要がある。
しかも ADOBE がPDF としてサポートしているのは UTF-16 だけであるので、必然的に
EBCDIC から UNIコードへの変換となる。
さらに ADOBE は仕様ミスをしていて
UTF-16 の半角文字は倍角表示となり、全角英数が半角表示となる。
というミスがある。
そこで EBCDIC で見つかった半角文字は全角に変換してから iconv で UTF-16 に
変換しなければならない。
ここで紹介する C/400ソース: TESTUTF16C は、このような ADOBE の問題にも対応している。
弊社ではこの toUTF16 関数を使って既に中国語の印刷スプールを PDF 化することに成功している。
【C/400ソース: TESTUTF16C】
0001.00 #include <stdio.h>
0002.00 #include <stdlib.h>
0003.00 #include <string.h>
0004.00 #include <qtqiconv.h>
0005.00 #include <locale.h>
0006.00 #include <signal.h>
0007.00 #include <errno.h>
0008.00
0009.00 #define TRUE 0
0010.00 #define FALSE -1
0011.00 #define UTF8 1208
0012.00 #define UTF16 1200
0013.00 #define USA 0
0014.00 #define JPN 1
0015.00 #define CHS 2
0016.00 #define CHT 3
0017.00 #define KOR 4
0018.00 #define THA 5
0019.00 #define DE 6
0020.00 #define KANA_SU 57
0021.00
0022.00 typedef struct {
0023.00 int BYTESPRO;
0024.00 int BYTESAVL;
0025.00 char MSGID[7];
0026.00 char RESRVD;
0027.00 char EXCPDATA[100];
0028.00 } ERRSTRUCTURE; /* Define the error return structure */
0029.00 ERRSTRUCTURE errcode;/* Error Code Structure for RCVMSG */
0030.00 volatile _INTRPT_Hndlr_Parms_T ca;
0031.00 int bINZSR = FALSE;
0032.00 char ref[133], asc_kana5035[KANA_SU + 1], asc_kana5026[KANA_SU + 1];
0033.00 int m_bLocale = FALSE;
0034.00
0035.00 void INZSR(void);
0036.00 int toUTF16(char* ebcbuf, char* unibuf, int CNTRY, int CVTDBCS, int H
0037.00 int setContryCode(int CNTRY);
0038.00 int toDBCS(char* schar, char* DBCS, int* DBLen, int ccsid);
0039.00 int toASCII(char* ascbuf, char* ebcbuf, char* table, char* tbllib, ..
0040.00 /*************************************************************/
0041.00 /* IMPORT 変 数 */
0042.00 /*************************************************************/
0043.00 /* CNTRY: 国 :0= 米国 1= 日本 2= 中国 3= 台湾 4= 韓国 5= タイ */
0044.00 /* 6= 独 */
0045.00 extern int CNTRY;
0046.00
0047.00 void main(void){
0048.00 char sBufLocal[128], sBufPDF[128];
0049.00 int cnvLen;
0050.00
0051.00 printf("** TESTUTF16C : UTF-16 への変換テスト **�n");
0052.00 getchar();
0053.00
0054.00 strcpy(sBufLocal, " 日本会社 CO,.LTD");
0055.00 printf(" 文字列 :%s( 長さ %d) を UTF-16 に変換します。 �n",
0056.00 sBufLocal, strlen(sBufLocal));
0057.00 getchar();
0058.00 cnvLen = toUTF16(sBufLocal, sBufPDF, CNTRY, TRUE, TRUE);
0059.00 if(cnvLen <= FALSE){/* 変換エラー */
0060.00 printf("UTF16 変換でエラーが発生しました。 �n");
0061.00 printf("[%d] 変換元データ :%s�n", __LINE__, sBufLocal);
0062.00 getchar();
0063.00 exit(-1);
0064.00 }/* 負数 */
0065.00 sBufPDF[cnvLen] = 0x00;
0066.00 printf(" 変換に成功しました。 ( 変換後の長さ = %d バイト )�n",
0067.00 cnvLen);
0068.00 getchar();
0069.00 exit(0);
0070.00 }
0071.00 /**********************************************************************
0072.00 int toUTF16(char* ebcbuf, char* unibuf, int uCNTRY, int CVTDBCS, int
0073.00 /**********************************************************************
0074.00 /* uCNTRY: 国 :0= 米国 1= 日本 2= 中国 3= 台湾 4= 韓国 5= タイ */
0075.00 /* 6= 独 7=Shift_JIS */
0076.00 /* toUTF16 は変換後のバッファーの長さを戻す */
0077.00 /* CVTDBCS: TRUE= 半角文字があれば全角文字に変換してから */
0078.00 /* UNICODE に変換する */
0079.00 /* HEXDSP : TRUE=HEX 形式で文字を出力する */
0080.00 /* */
0081.00 /*-------------------------------------------------------------------*/
0082.00 {
0083.00 int JOB_CCSID;
0084.00 int len, i, j, DBLen, bCNTRY;
0085.00 iconv_t cd;
0086.00 QtqCode_T fromcode, tocode;
0087.00 size_t inbyte, outbyte, rc, bckbyte;
0088.00 char* source, *target, *hexbuf, *DBCSbuf;
0089.00 char hexdsp[3];
0090.00
0091.00 if(bINZSR == FALSE) INZSR();
0092.00 JOB_CCSID = setContryCode(uCNTRY);
0093.00 memset(&fromcode, 0, sizeof(fromcode));
0094.00 memset(&tocode, 0, sizeof(tocode));
0095.00 fromcode.CCSID = JOB_CCSID;
0096.00 tocode.CCSID = UTF16;
0097.00
0098.00 /*(1) 半角文字を倍角に変更する */
0099.00 if(CVTDBCS == TRUE){/* 倍角に変更 */
0100.00 len = strlen(ebcbuf);
0101.00 DBCSbuf = (char*)malloc(len * 2 + 2);
0102.00 toDBCS(ebcbuf, DBCSbuf, &DBLen, JOB_CCSID);
0103.00 memcpy(ebcbuf, DBCSbuf, DBLen);
0104.00 free(DBCSbuf);
0105.00 ebcbuf[DBLen] = 0x00;
0106.00 }/* 倍角に変更 */
0107.00
0108.00 /*(2) 変換ハンドルを作成 */
0109.00 cd = QtqIconvOpen(&tocode, &fromcode);
0110.00 if(cd.return_value == FALSE){/* オープン・エラー */
0111.00 printf("UNI_CODE-ERR[%d] QtqIconvOpen :%s�n", __LINE__, strerror(er
0112.00 return FALSE;
0113.00 }/* オープン・エラー */
0114.00 source = ebcbuf;
0115.00 target = unibuf;
0116.00 inbyte = strlen(ebcbuf);
0117.00 outbyte = strlen(ebcbuf) * 2;
0118.00 bckbyte = outbyte;
0119.00
0120.00 /*(3) 変換を実行 */
0121.00 rc = iconv(cd, &source, &inbyte, &target, &outbyte);
0122.00 if(rc != 0){/* 変換エラー */
SOSI printf("UNI_CODE iconv:JOB から UTF-16 への変換でエラーが発生しまし
0124.00 printf("UNI_CODE-ERR[%d] iconv :[%d]%s�n",__LINE__,errno,strerror
0125.00 iconv_close(cd);
0126.00 getchar();
0127.00 exit(-1);
0128.00 }/* 変換エラー */
0129.00
0130.00 inbyte = strlen(ebcbuf);
0131.00 if(outbyte > bckbyte)
0132.00 outbyte = bckbyte - outbyte;
0133.00 unibuf[(int)outbyte] = 0x00;
0134.00 /*(4) 変換ハンドルをクローズ */
0135.00 iconv_close(cd);
0136.00
0137.00 /*(5) HEXDSP 出力 */
0138.00 if(HEXDSP == TRUE){/* HEXDSP 出力 */
0139.00 len = (int)outbyte;
0140.00 while(len > 0){/*while*/
0141.00 if(len > 1 && unibuf[len-1] == 0x00){/* 末尾が NULL */
0142.00 len --;
0143.00 }/* 末尾が NULL */
0144.00 else break;
0145.00 }/*while*/
0146.00 hexbuf = (char*)malloc(len * 2 + 3);
0147.00 #pragma convert(850)
0148.00 hexbuf[0] = '<';
0149.00 #pragma convert(0)
0150.00 j = 1;
0151.00 bCNTRY = CNTRY;
0152.00 CNTRY = 1; /* 日本 */
0153.00 for(i = 0; i<len; i++){/*for-loop*/
0154.00 sprintf(hexdsp, "%02X", unibuf[i]);
0155.00 hexdsp[2] = 0x00;
0156.00 toASCII(&hexbuf[j], hexdsp, "ASCII5035 ", "SPOOLWTR ");
0157.00 j += 2;
0158.00 }/*for-loop*/
0159.00 CNTRY = bCNTRY;
0160.00 #pragma convert(850)
0161.00 hexbuf[j] = '>';
0162.00 #pragma convert(0)
0163.00 j ++;
0164.00 hexbuf[j] = 0x00;
0165.00 memcpy(unibuf,hexbuf,j);
0166.00 free(hexbuf);
0167.00 return j;
0168.00 }/* HEXDSP 出力 */
0169.00 else return (int)outbyte;
0170.00 }
0171.00 /****************/
0172.00 void INZSR(void)
0173.00 /****************/
0174.00 {
0175.00 char kana5035[]=
0176.00 "アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワヲンァゥェォ
0177.00 char kana5026[]=
0178.00 "abcdefghiテナニヌネ jklmnopqrノフヘホstuvwxyzマム[メモロワン・]ヲィゥェ
0179.00
0180.00 int i;
0181.00
0182.00 if(bINZSR == TRUE) return;
0183.00 toASCII(asc_kana5035, kana5035, "ASCII5035 ", "SPOOLWTR ");
0184.00 toASCII(asc_kana5026, kana5026, "ASCII5026 ", "SPOOLWTR ");
0185.00 bINZSR = TRUE;
0186.00 }
0187.00 /**********************************************************/
0188.00 int toDBCS(char* schar, char* DBCS, int* DBLen, int ccsid)
0189.00 /**********************************************************/
0190.00 {
0191.00 char kana5035[]= "アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワヲンァゥェォ
0192.00 abcdefghijklmnopqrstuvwxyzッィ[]^~「」・。、\$";
0193.00 char kana5026[]= "abcdefghiテナニヌネ jklmnopqrノフヘホstuvwxyzマム[メモロワン・]ヲィゥェ
0194.00 イウエオカキクケサシスセソタチツトハミヤユヨラリルレョァ 。「、 」$��";
0195.00 char KANA5026[]= "abcdefghiテナニヌネ jklmnopqrノフヘホstuvwxyzマム[メモロワン・]ヲィゥェ
0196.00 int bKJ, i, j, pos, bHF = FALSE;
0197.00 char ch;
0198.00 char* ptr;
0199.00
0200.00 if(m_bLocale == FALSE){/*LOCALE 対応 */
0201.00 setlocale(LC_CTYPE, "/QSYS.LIB/JA_5035.LOCALE");
0202.00 m_bLocale = TRUE;
0203.00 }/*LOCALE 対応 */
0204.00 if(ccsid != 5026){/* ccsid=5035 */
0205.00 bKJ = FALSE;
0206.00 for(i = 0; i<strlen(schar); i++){/*for-loop*/
0207.00 if(bKJ == FALSE){/* 非漢字 */
0208.00 if(schar[i] == 0x0e){/* OE */
0209.00 bKJ = TRUE; continue;
0210.00 }/* OE */
0211.00 ch = schar[i];
0212.00 ptr = strchr(kana5035, ch);
0213.00 if(ptr != NULL){/* カナを補正 */
0214.00 pos = (int)(ptr - kana5035);
0215.00 schar[i] = kana5026[pos];
0216.00 }/* カナを補正 */
0217.00 }/* 非漢字 */
0218.00 else{/* 漢字 */
0219.00 if(schar[i] == 0x0f) bKJ = FALSE;
0220.00 }/* 漢字 */
0221.00 }/*for-loop*/
0222.00 }/* ccsid=5035 */
0223.00
0224.00 bKJ = FALSE;
0225.00 bHF = FALSE; /* 半角 */
0226.00 j = 0;
0227.00 for(i = 0; i<strlen(schar); i++){/*for-loop*/
0228.00 ch = schar[i];
0229.00 if(bKJ == FALSE){/* 非漢字 */
0230.00 if(schar[i] == 0x0e){/* OE */
0231.00 if(bHF == TRUE){/* 半角の終わり */
0232.00 DBCS[j] = 0x0f; j ++;
0233.00 }/* 半角の終わり */
0234.00 DBCS[j] = schar[i]; j++;
0235.00 bKJ = TRUE; bHF = FALSE; continue;
0236.00 }/* OE */
0237.00 if(bHF == FALSE){/* 初めての半角 */
0238.00 DBCS[j] = 0x0e; j++;
0239.00 bHF = TRUE;
0240.00 }/* 初めての半角 */
0241.00 if(ch == 0x40){/* ブランク */
0242.00 DBCS[j] = 0x40; j++;
0243.00 }/* ブランク */
0244.00 else if((ptr = strchr(KANA5026, ch)) != NULL){/* 半角カナ */
0245.00 DBCS[j] = 0x43; j++;
0246.00 }/* 半角カナ */
0247.00 else{/* 半角英数 */
0248.00 DBCS[j] = 0x42; j++;
0249.00 }/* 半角英数 */
0250.00 DBCS[j] = ch; j++;
0251.00 }/* 非漢字 */
0252.00 else{/* 漢字 */
0253.00 DBCS[j] = schar[i]; j++;
0254.00 if(schar[i] == 0x0f) bKJ = FALSE;
0255.00 }/* 漢字 */
0256.00 }/*for-loop*/
0257.00 if(bHF == TRUE){/* 半角の終わり */
0258.00 DBCS[j] = 0x0f; j ++;
0259.00 }/* 半角の終わり */
0260.00 DBCS[j] = 0x00;
0261.00 *DBLen = j;
0262.00
0263.00 return TRUE;
0264.00 }
0265.00 /*****************************/
0266.00 int setContryCode(int CNTRY)
0267.00 /*****************************/
0268.00 /* CNTRY: 国 :0= 米国 1= 日本 2= 中国 3= 台湾 4= 韓国 5= タイ */
0269.00 /* 6= 独 7=Shift_JIS */
0270.00 {
0271.00 int JOB_CCSID;
0272.00
0273.00 switch(CNTRY){/*switch*/
0274.00 case 0: JOB_CCSID = 37; break; /* ENU */
0275.00 case 1: JOB_CCSID = 5026; break; /* JPN */
0276.00 case 2: JOB_CCSID = 935; break; /* CHS */
0277.00 case 3: JOB_CCSID = 937; break; /* CHT */
0278.00 case 4: JOB_CCSID = 933; break; /* KOR */
0279.00 case 5: JOB_CCSID = 838; break; /* THA */
0280.00 case 6: JOB_CCSID = 273; break; /* DEU */
0281.00 case 7: JOB_CCSID = 943; break; /* Shift_JIS */
0282.00 }/*switch*/
0283.00 return JOB_CCSID;
0284.00 }

【コンパイル】
・CRTCMOD MODULE(QTEMP/TESTUTF16C) SRCFILE(MYSRCLIB/QCSRC) AUT(*ALL) ・CRTPGM PGM(MYLIB/TESTUTF16C) MODULE(QTEMP/TESTUTF16C) BNDSRVPGM(CVTMOD4) ACTGRP(*NEW) AUT(*ALL)
【解説】
toASCII 関数は弊社独自の Spoolライターの関数であり、そのためコンパイルでは
サービス・プログラム CVTMOD4 をバインドしている。
読者は toASCII 関数の代わりに API: QDCXLATE を使ってもよいが、製品として組み込むのであれば
QDCXLATE は半角文字等の変換においてバグが多いので注意が必要である。
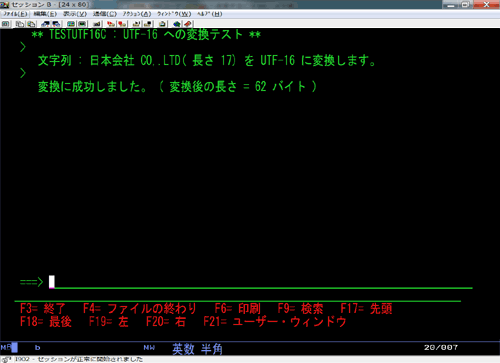
【実行結果】