99. 国際言語の入出力をサポートするには (2)
国際言語化をサポートするためには Unicdoe (UTF-8) が
キー・ポイントになることはご理解頂けたと思う。
この Unicode (UTF-8)を扱う方法についてもう少し掘り下げて説明しよう。
■ Unicode 変換は N:1 の関係
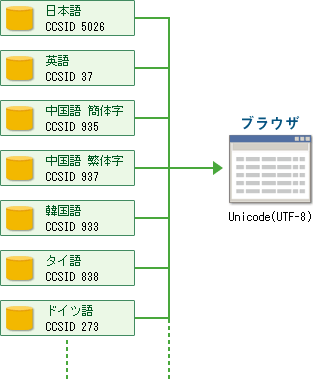
左辺にある各国語データ・ベースは Unicode 変換によって右辺にあるブラウザへ
Unicode として変換されている。(出力)
ところが逆の場合は、この構造は左辺が N 、右辺が 1 の N:1 の関係にあるので
ブラウザからはどの言語コードに戻せば良いかを判定することができない。
左辺の N 個に分かれている要因は国である。
従って 右辺から左辺に戻すため(入力)は、国を判断する必要がある。
幸い、ブラウザで設定しておいた言語は、ブラウザによってWebサーバーには
Accept-Language: ja, zh-cn
のように情報が HTTPプロトコルの一部として戻される。
これによって サーバー側では、どの国の CCSID に戻せばよいかを判断することができるのである。
■ ブラウザからの入力コードは不明である
前出の「Accept-Language」 でブラウザから入力された国をサーバーで知ることが
できることは理解できした。
しかしブラウザから入力したコードが Shift_JIS であったのか
UTF-8 であったのかをどのようにしてサーバーは知ることができるのだろうか ?
実は、その情報は全くサーバー側には伝えられていない。
ブラウザから入力された文字列は例えば「池田」という文字列は Shift_JIS では
X'92729363' であるので、ブラウザは、これを %92%72%93%63 とエンコードして
サーバーへ送信する。
サーバー側ではこれを HEX に合成し直すこと(デコード)はできるが
これは ASCII の漢字であるとは判断することはできない。
Unicode が入ってくる可能性もあるなら %92%72%93 を Unicode のひとつの漢字として
見なさなければならないからである。
HTML 上で、charset=Shift_JIS や charset=utf-8 を記述していても
これらの情報はサーバーに伝わってこないのであればサーバーは、どのような
コードが入力されたのかを判別する方法がない。
それでは全世界の Webサーバーで毎日、数え切れない莫大な入力が行なわれているのに
何故このような問題がサイトで騒がれていないのだろうか ?
それは一般的な Webサーバーの大半が UNIX/IIS 等の ASCII ベースであるからである。
このような オープン系のサーバーでは System i のように EBCDIC/ASCII 変換の
ような文字変換の必要がない。
また ASCII/Unicode の混在があったとしても、各々のアプリではどのコードで
処理するかは決まっていて、デコード処理き各アプリが自分でデコードするからである。
IBM System i の場合でも開発者が自分でデコードする、というのであれば
この問題は起こらない。
しかしRPG 開発者が自らデコードする CGI を書くということは非常に稀れであり
大抵は何らかのツールに頼ってるはずである。
つまりデコードはツール任せなのでブラウザからの入力は何のコードであるかと
いうことをツールに明確に提示しなければならないのである。
EnterpriseServer の場合は
<input type="hidden" name=CHARSET value="UTF-8">
という文字列を HTML に埋め込むことで CHARSET=UTF-8 という情報が
サーバー側へ送られてくるようにしている。
【 一般的な解決案 】
サイトで良く紹介されている解決案は
document.charset='EUC-JP';
という JavaScript によってUTF-8 の HTML からの入力値を Shift_JIS に
強制的に変換してしまうというものが最も多い解決案のようです。
しかしこの方法では国際言語対応には全く向いていません。
中国語や韓国語も日本語に変換されていまうからです。
Unicode の HTML は何の目的で使用されているかということを
見誤っているのではないかと思われます。
【 Google の解決案 】
Google に文字コードを明示的に宣言して SUBMIT 投入するには
<input type="hidden" name="ie" value="UTF-8">
という文字列を HTML に埋め込みます。
これは奇しくも EnterpriseServer と同じ解決方法である。
■ EBCDIC/Unicode は iconv で変換
EBCDIC コードを ASCII へ変換するのはお馴染みのAPI:QDCXLATE であるが
QDCXLATE では EBCDIC/UTF-8 の変換を行なうことはできない。
Unicode への変換は UNIX 関数でもある iconv という関数によって行なうことになる。
EBCDIC/UTF-8 の変換もツールに頼るのであれば開発者で iconv を使うことも
ないかもしれないが IBM System i の製品で Unicode 変換をサポートしている
製品はほとんど見当たらない。
iconv の使い方は別途、C/400, CLP, RPG での使用方法を紹介する予定である。