38. 作って理解する SQLストアド・プロシージャー (1)
ストアド・プロシージャーと聞くと ODBCユーザー以外は、何やら SQL の難しいモノという
イメージがあり、普段の馴染みはほとんどないだろう。
ODBC を利用しているユーザーであっても PCクライアント側から SQLストアド・プロシージャーを
指定するだけなので、どのような内容であるのか知らないままに利用しているだけ、
というのが正直なところであるかもしれない。
SQLストアド・プロシージャーの理解を困難にしているのは、IBMマニュアルに紹介されている、
SQLストアド・プロシージャーのサンプル・ソースが C言語で書かれているものがほとんどであり、
しかもサンプル・ソースの解読がやさしくないソースであることと、何よりも正しく動作しない、
またはコンパイル・エラーとなるソースだからである。
SQLストアド・プロシージャーこのシリーズでは、
- RPG でストアド・プロシージャーと ODBC を記述する
- 確実に動作するサンプル・ソースを紹介する
(当たり前の話であるが)
を大前提として紹介していく。
まず、最初に「ストアド・プロシージャー」とは何だろう ?
ストアド・プロシージャーとは下記の図のような構成によって ODBC(Open DataBase Connectivity) に
よってデータ・ベースに SQL接続できるアーキテクチャーである。
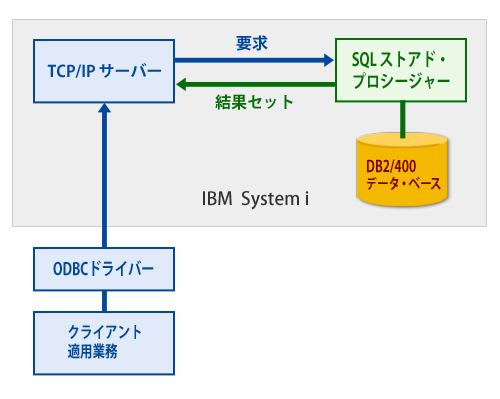
要はリモートで SQL文を発行してデータにアクセスする仕組みのことであり、一般には
SQLストアド・プロシージャーは SQLデータ・セットを保管しておくので毎度、SQL要求を
発行するよりはパフォーマンスに優れている、と言われているがそれは厳密には正しくない。
確かに対話式に SQL を発行するよりはストアド・プロシージャーのほうが
パフォーマンスは良くなるが、それは System i の SQL の仕組みのせいである。
このことについては後で詳しく解説する。
SQLストアド・プロシージャーは SQL で作成されるのはもちろんのこと、
RPG や C言語をはじめとする他の開発言語で作成することができる。
つまり、ODBC のプロトコルにさえ準拠していれば、どのような開発言語によっても
ストアド・プロシージャーを作ることができる。
極端に言えば CLP で作成することもできるのだ。
このことは ODBC の機能を大幅に拡張させることを意味する。
SQL文だけでできないデータ処理の方法を RPG などの言語によって拡張することができるからである。
例えば、SELECT ではできない、複数のファイルの読み取りや SQL の UPDATE だけでは
できない複雑な多くのデータの更新、といったことも RPG で記述すれば何の問題もない。
COMIT & ROLLBK も使うことができる。
RPG で作ったストアド・プロシージャーであっても ODBCクライアントから見れば
ただのストアド・プロシージャーに変わりはないので特別な仕組みは必要ない。
つまり、ストアド・プロシージャーは処理の内容をカプセル化できるオブジェクト指向でもある。